
Adapatado do Original: Tray Hunner – Python Morsels Python tip: create looping helpers Python’s for loops are all about looping over an iterable. That is their sole purpose. Since Python’s for loops are more special-purposed than some programming languages, we need to embrace loopers to …

Como sabemos, a água possui um elevado calor específico (1,00 [cal/g.°C]), em outras palavras, ela não varia de temperatura “facilmente”. As regiões do planeta terra que possuem água em abundância, seja no mar ou na atmosfera, se beneficiam desta propriedade e, portanto, têm a variação de temperatura amenizada devido a esta propriedade da água.
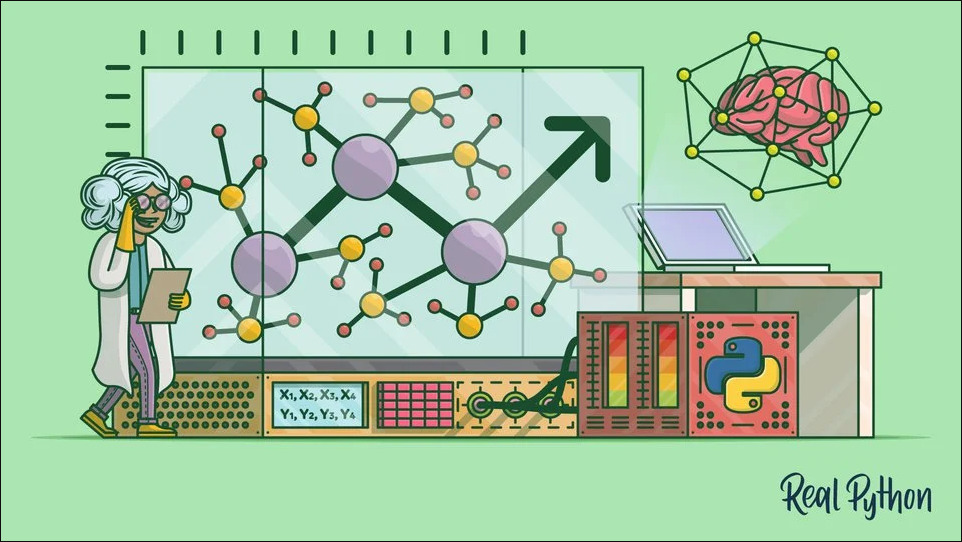
Neste tutorial passo a passo, você vai começar com regressão linear em Python. A regressão linear é uma das técnicas fundamentais de estatística e aprendizado de máquina, e python é uma escolha popular para aprendizado de máquina Original: https://realpython.com/linear-regression-in-python/ Linear …
Adaptado do original: Why does numpy std() give a different result to matlab std()? PERGUNTA I try to convert matlab code to numpy and figured out that numpy has a different result with the std function. in matlab std([1,3,4,6]) ans …
Radiação de Corpo Negro, teoria disponível em: http://coral.ufsm.br/gef/Moderna/moderna02.pdfDados gerados: https://plot.ly/~zrhans/408/ https://plot.ly/embed.js