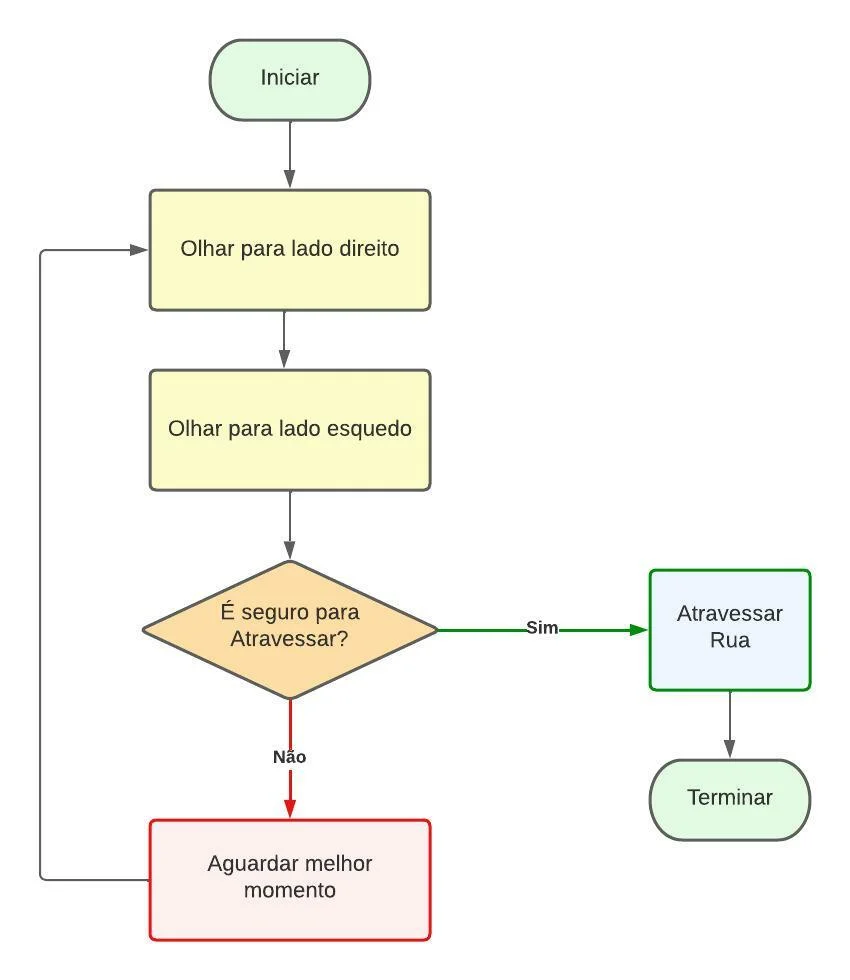
FSC1189 – ALGORITMO E PROGRAMAÇÃO Seu Estado Não Inscrito Enroll in this curso to get access Preço Grátis Comece Agora Log In to Enroll